pytorch - 生态和部署
1 生态
PyTorch生态在图像、视频、文本等领域中的发展。
1.1 torchvision
torchvision包含了在计算机视觉中常常用到的数据集,模型和图像处理的方式。
- torchvision.datasets *
torchvision.datasets主要包含了一些我们在计算机视觉中常见的数据集 - torchvision.models *
各种预训练好的模型 - torchvision.tramsforms *
图像处理的方法 - torchvision.io
在torchvision.io提供了视频、图片和文件的 IO 操作的功能,它们包括读取、写入、编解码处理操作。随着torchvision的发展,io也增加了更多底层的高效率的API。 - torchvision.ops
torchvision.ops 为我们提供了许多计算机视觉的特定操作,包括但不仅限于NMS,RoIAlign(MASK R-CNN中应用的一种方法),RoIPool(Fast R-CNN中用到的一种方法)。在合适的时间使用可以大大降低我们的工作量,避免重复的造轮子。 - torchvision.utils
torchvision.utils 为我们提供了一些可视化的方法,可以帮助我们将若干张图片拼接在一起、可视化检测和分割的效果。
1.2 PyTorchVideo
PyTorchVideo 是一个专注于视频理解工作的深度学习库。
1.3 torchtext
用于自然语言处理(NLP)的工具包torchtext。方便的对文本进行预处理,例如截断补长、构建词表等。
- 构建数据集
- Field及其使用
Field是torchtext中定义数据类型以及转换为张量的指令。torchtext 认为一个样本是由多个字段(文本字段,标签字段)组成,不同的字段可能会有不同的处理方式,所以才会有 Field 抽象。定义Field对象是为了明确如何处理不同类型的数据,但具体的处理则是在Dataset中完成的。sequential设置数据是否是顺序表示的;1
2
3tokenize = lambda x: x.split()
TEXT = data.Field(sequential=True, tokenize=tokenize, lower=True, fix_length=200)
LABEL = data.Field(sequential=False, use_vocab=False)
tokenize用于设置将字符串标记为顺序实例的函数;
lower设置是否将字符串全部转为小写;
fix_length设置此字段所有实例都将填充到一个固定的长度,方便后续处理;
use_vocab设置是否引入Vocab object,如果为False,则需要保证之后输入field中的data都是numerical的;
构建Field完成后就可以进一步构建dataset了这里使用数据csv_data中有”comment_text”和”toxic”两列,分别对应text和label1
2
3
4
5
6
7
8
9
10
11
12
13
14from torchtext import data
def get_dataset(csv_data, text_field, label_field, test=False):
fields = [("id", None), # we won't be needing the id, so we pass in None as the field
("comment_text", text_field), ("toxic", label_field)]
examples = []
if test:
# 如果为测试集,则不加载label
for text in tqdm(csv_data['comment_text']):
examples.append(data.Example.fromlist([None, text, None], fields))
else:
for text, label in tqdm(zip(csv_data['comment_text'], csv_data['toxic'])):
examples.append(data.Example.fromlist([None, text, label], fields))
return examples, fields可以看到,定义Field对象完成后,通过get_dataset函数可以读入数据的文本和标签,将二者(examples)连同field一起送到torchtext.data.Dataset类中,即可完成数据集的构建。使用以下命令可以看下读入的数据情况1
2
3
4
5
6
7
8
9
10
11
12
13
14train_data = pd.read_csv('train_toxic_comments.csv')
valid_data = pd.read_csv('valid_toxic_comments.csv')
test_data = pd.read_csv("test_toxic_comments.csv")
TEXT = data.Field(sequential=True, tokenize=tokenize, lower=True)
LABEL = data.Field(sequential=False, use_vocab=False)
# 得到构建Dataset所需的examples和fields
train_examples, train_fields = get_dataset(train_data, TEXT, LABEL)
valid_examples, valid_fields = get_dataset(valid_data, TEXT, LABEL)
test_examples, test_fields = get_dataset(test_data, TEXT, None, test=True)
# 构建Dataset数据集
train = data.Dataset(train_examples, train_fields)
valid = data.Dataset(valid_examples, valid_fields)
test = data.Dataset(test_examples, test_fields)1
2
3
4
5# 检查keys是否正确
print(train[0].__dict__.keys())
print(test[0].__dict__.keys())
# 抽查内容是否正确
print(train[0].comment_text) - 词汇表(vocab)
Word Embedding 的基本思想是收集一个比较大的语料库(尽量与所做的任务相关),在语料库中使用word2vec之类的方法构建词语到向量(或数字)的映射关系,之后将这一映射关系应用于当前的任务,将句子中的词语转为向量表示。在torchtext中可以使用Field自带的build_vocab函数完成词汇表构建。1
TEXT.build_vocab(train)
- 数据迭代器
相当于dataloader1
2
3
4
5
6
7
8
9
10
11
12
13
14from torchtext.data import Iterator, BucketIterator
# 若只针对训练集构造迭代器
# train_iter = data.BucketIterator(dataset=train, batch_size=8, shuffle=True, sort_within_batch=False, repeat=False)
# 同时对训练集和验证集进行迭代器的构建
train_iter, val_iter = BucketIterator.splits(
(train, valid), # 构建数据集所需的数据集
batch_sizes=(8, 8),
device=-1, # 如果使用gpu,此处将-1更换为GPU的编号
sort_key=lambda x: len(x.comment_text), # the BucketIterator needs to be told what function it should use to group the data.
sort_within_batch=False
)
test_iter = Iterator(test, batch_size=8, device=-1, sort=False, sort_within_batch=False) - 使用自带数据集
若干常用的数据集
- Field及其使用
- 评测指标(metric)
NLP中部分任务的评测不是通过准确率等指标完成的,比如机器翻译任务常用BLEU (bilingual evaluation understudy) score来评价预测文本和标签文本之间的相似程度。torchtext中可以直接调用torchtext.data.metrics.bleu_score来快速实现BLEU1
2
3
4from torchtext.data.metrics import bleu_score
candidate_corpus = [['My', 'full', 'pytorch', 'test'], ['Another', 'Sentence']]
references_corpus = [[['My', 'full', 'pytorch', 'test'], ['Completely', 'Different']], [['No', 'Match']]]
bleu_score(candidate_corpus, references_corpus) - 其他
由于NLP常用的网络结构比较固定,torchtext并不像torchvision那样提供一系列常用的网络结构。模型主要通过torch.nn中的模块来实现,比如torch.nn.LSTM、torch.nn.RNN等。
2 模型部署
将PyTorch训练好的模型转换为ONNX 格式,然后使用ONNX Runtime运行它进行推理。将得到的权重进行变换才能使我们的模型可以成功部署在上述设备上。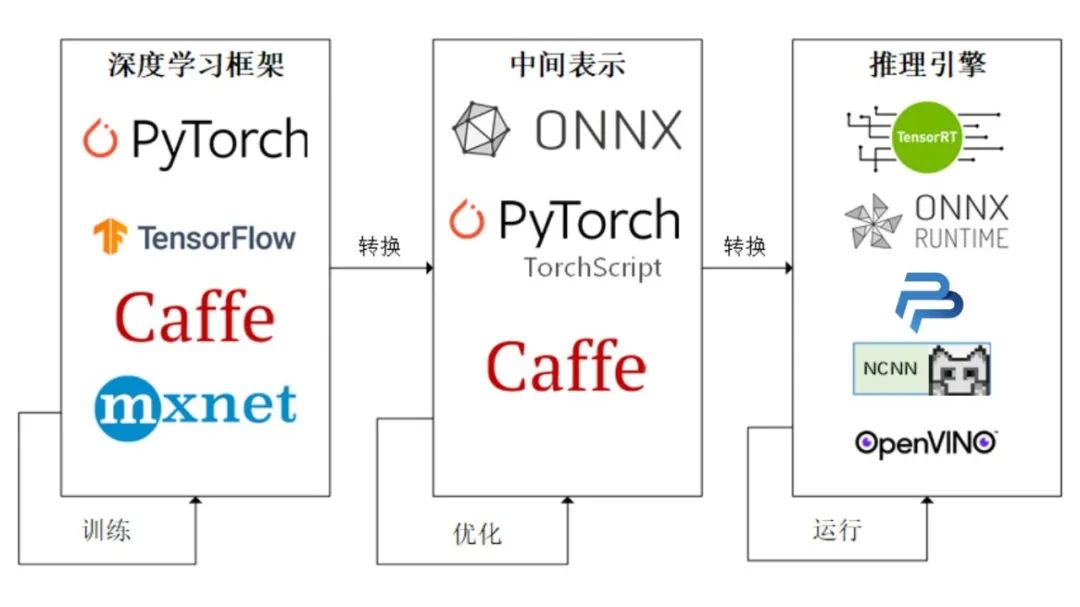
2.1 使用ONNX进行部署并推理
ONNX Runtime 是由微软维护的一个跨平台机器学习推理加速器,它直接对接ONNX,可以直接读取.onnx文件并实现推理,不需要再把 .onnx 格式的文件转换成其他格式的文件。PyTorch借助ONNX Runtime也完成了部署的最后一公里,构建了 PyTorch –> ONNX –> ONNX Runtime 部署流水线,我们只需要将模型转换为 .onnx 文件,并在 ONNX Runtime 上运行模型即可。
2.2 ONNX和ONNX Runtime简介
1 | # 激活虚拟环境 |
2.3 模型导出为ONNX
- 模型转换为ONNX格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import torch.onnx
# 转换的onnx格式的名称,文件后缀需为.onnx
onnx_file_name = "xxxxxx.onnx"
# 我们需要转换的模型,将torch_model设置为自己的模型
model = torch_model
# 加载权重,将model.pth转换为自己的模型权重
# 如果模型的权重是使用多卡训练出来,我们需要去除权重中多的module. 具体操作可以见5.4节
model = model.load_state_dict(torch.load("model.pth"))
# 导出模型前,必须调用model.eval()或者model.train(False)
model.eval()
# dummy_input就是一个输入的实例,仅提供输入shape、type等信息
batch_size = 1 # 随机的取值,当设置dynamic_axes后影响不大
dummy_input = torch.randn(batch_size, 1, 224, 224, requires_grad=True)
# 这组输入对应的模型输出
output = model(dummy_input)
# 导出模型
torch.onnx.export(model, # 模型的名称
dummy_input, # 一组实例化输入
onnx_file_name, # 文件保存路径/名称
export_params=True, # 如果指定为True或默认, 参数也会被导出. 如果你要导出一个没训练过的就设为 False.
opset_version=10, # ONNX 算子集的版本,当前已更新到15
do_constant_folding=True, # 是否执行常量折叠优化
input_names = ['input'], # 输入模型的张量的名称
output_names = ['output'], # 输出模型的张量的名称
# dynamic_axes将batch_size的维度指定为动态,
# 后续进行推理的数据可以与导出的dummy_input的batch_size不同
dynamic_axes={'input' : {0 : 'batch_size'},
'output' : {0 : 'batch_size'}}) - ONNX模型的检验
1
2
3
4
5
6
7
8
9
10import onnx
# 我们可以使用异常处理的方法进行检验
try:
# 当我们的模型不可用时,将会报出异常
onnx.checker.check_model(self.onnx_model)
except onnx.checker.ValidationError as e:
print("The model is invalid: %s"%e)
else:
# 模型可用时,将不会报出异常,并会输出“The model is valid!”
print("The model is valid!") - ONNX可视化
Netron
2.4 使用ONNX Runtime进行推理
1 | # 导入onnxruntime |
- PyTorch模型的输入为tensor,而ONNX的输入为array,因此我们需要对张量进行变换或者直接将数据读取为array格式,我们可以实现下面的方式进行张量到array的转化。
1
2def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy() - 输入的array的shape应该和我们导出模型的dummy_input的shape相同,如果图片大小不一样,我们应该先进行resize操作。
- run的结果是一个列表,我们需要进行索引操作才能获得array格式的结果。
- 在构建输入的字典时,我们需要注意字典的key应与导出ONNX格式设置的input_name相同,因此我们更建议使用上述的第二种方法构建输入的字典。
2.5 代码实战
pytorch- EXPORTING A MODEL FROM PYTORCH TO ONNX AND RUNNING IT USING ONNX RUNTIME
参考资料
pytorch - 生态和部署

