pytorch - 模型定义
模型定义的方式
基于nn.Module,可以通过Sequential,ModuleList和ModuleDict三种方式定义PyTorch模型。
Sequential
将模型的层按序排列起来,按顺序读取,不用写forward,但丧失灵活性
- Sequential
1
2
3
4
5
6
7
8## Sequential: Direct list
import torch.nn as nn
net1 = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
print(net1)Sequential( (0): Linear(in_features=784, out_features=256, bias=True) (1): ReLU() (2): Linear(in_features=256, out_features=10, bias=True) ) - Ordered Dict
1
2
3
4
5
6
7
8import collections
import torch.nn as nn
net2 = nn.Sequential(collections.OrderedDict([
('fc1', nn.Linear(784, 256)),
('relu1', nn.ReLU()),
('fc2', nn.Linear(256, 10))
]))
print(net2)Sequential( (fc1): Linear(in_features=784, out_features=256, bias=True) (relu1): ReLU() (fc2): Linear(in_features=256, out_features=10, bias=True) )
ModuleList
ModuleList 接收一个子模块(或层,需属于nn.Module类)的列表作为输入,类似List那样进行append和extend操作。同时,子模块或层的权重也会自动添加到网络中来。
1 | net3 = nn.ModuleList([nn.Linear(784, 256), nn.ReLU()]) |
ModuleList 并没有定义一个网络,它只是将不同的模块储存在一起。把modellist写到初始化,再定义forward函数明确传输顺序。
1 | class Net3(nn.Module): |
ModuleDict
ModuleDict和ModuleList的作用类似,只是ModuleDict能够更方便地为神经网络的层添加名称。同样地,ModuleDict并没有定义一个网络,它只是将不同的模块储存在一起,要定义forward。
1 | net = nn.ModuleDict({ |
利用模型块快速搭建复杂网络
当模型有很多层的时候,其中很多重复出现的结构可以定义为一个模块,便利模型构建。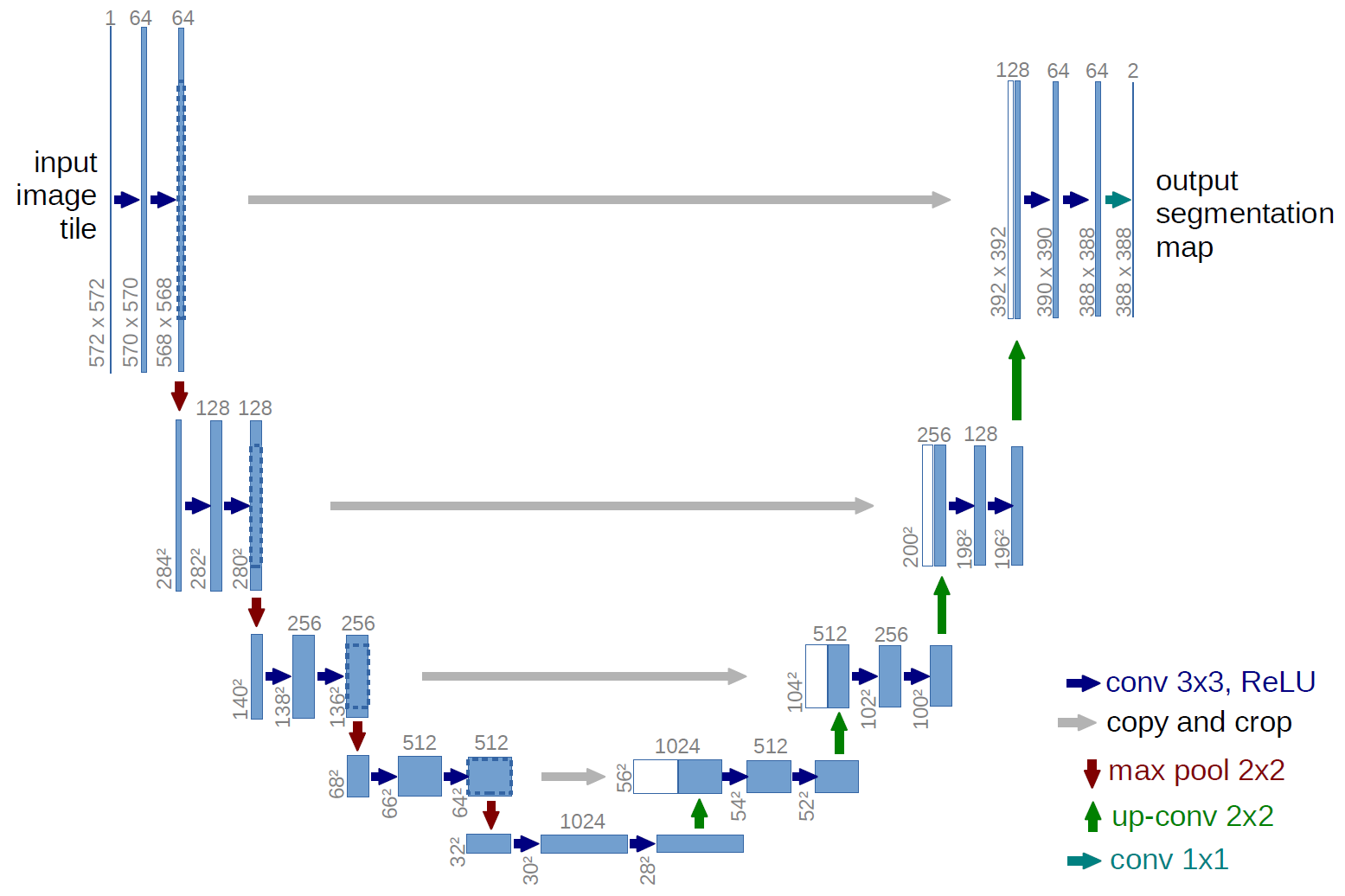
如U-Net所示,模型左右对称,每个子层内部有两次卷积,左侧下采样连接,右侧上采样连接,每层模型块和上下模型块连接,同层的左右模型块连接。
- 双次卷积
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x) - 下采样
1
2
3
4
5
6
7
8
9
10
11
12class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x) - 上采样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear: # 插值
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
# 连接左侧的数据再卷积
return self.conv(x) - 输出
1
2
3
4
5
6
7class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x) - 组装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
unet = UNet(3,1)
unet
模型修改
当有一个现成的模型需要对结构进行修改使用时,我们可以在已有模型上修改。
- 修改模型层先复制,然后修改outc
1
2
3import copy
unet1 = copy.deepcopy(unet)
unet1.outc要把输出Chanel变成5,重新实例化outc1
2
3b = torch.rand(1,3,224,224)
out_unet1 = unet1(b)
print(out_unet1.shape)1
2
3
4unet1.outc = OutConv(64, 5)
unet1.outc
out_unet1 = unet1(b)
print(out_unet1.shape) - 添加额外输入或用torch.cat实现了tensor的拼接,如x = torch.cat((self.dropout(self.relu(x)), add_variable.unsqueeze(1)),1)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37class UNet2(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet2, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x, add_variable):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
x = x + add_variable #修改点
logits = self.outc(x)
return logits
unet2 = UNet2(3,1)
c = torch.rand(1,1,224,224)
out_unet2 = unet2(b, c)
print(out_unet2.shape) - 添加额外输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36class UNet3(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet3, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits, x5 # 修改点
unet3 = UNet3(3,1)
c = torch.rand(1,1,224,224)
out_unet3, mid_out = unet3(b)
print(out_unet3.shape, mid_out.shape)
模型保存和读取
单卡/多卡,整个/部分模型, unet.state_dict()查看模型权重,保存的模型格式: pt pth pkl。
CPU或单卡:保存&读取整个模型
1
2
3torch.save(unet, "./unet_example.pth")
loaded_unet = torch.load("./unet_example.pth")
loaded_unet.state_dict()CPU或单卡:保存&读取模型权重
1
2
3
4torch.save(unet.state_dict(), "./unet_weight_example.pth")
loaded_unet_weights = torch.load("./unet_weight_example.pth")
unet.load_state_dict(loaded_unet_weights) # 用已经定义好的模型结构加载变量
unet.state_dict()多卡:保存&读取整个模型。注意模型层名称前多了module
不建议,因为保存模型的GPU_id等信息和读取后训练环境可能不同,尤其是要把保存的模型交给另一用户使用的情况1
2
3
4
5
6os.environ['CUDA_VISIBLE_DEVICES'] = '2,3'
unet_mul = copy.deepcopy(unet)
unet_mul = nn.DataParallel(unet_mul).cuda()
torch.save(unet_mul, "./unet_mul_example.pth")
loaded_unet_mul = torch.load("./unet_mul_example.pth")
loaded_unet_mul多卡:保存&读取模型权重。
1
2
3
4
5torch.save(unet_mul.state_dict(), "./unet_weight_mul_example.pth")
loaded_unet_weights_mul = torch.load("./unet_weight_mul_example.pth")
unet_mul.load_state_dict(loaded_unet_weights_mul)
unet_mul = nn.DataParallel(unet_mul).cuda()
unet_mul.state_dict()另外,如果保存的是整个模型,也建议采用提取权重的方式构建新的模型:
1
2
3unet_mul.state_dict = loaded_unet_mul.state_dict
unet_mul = nn.DataParallel(unet_mul).cuda()
unet_mul.state_dict()
参考资料
pytorch - 模型定义

