pytorch - 各个组件和实践
本章介绍pytorch进行深度学习模型训练的各个组件和实践,层层搭建神经网络模型。
神经网络学习机制

- 数据预处理
完成一项机器学习任务时的步骤,首先需要对数据进行预处理,其中重要的步骤包括数据格式的统一和必要的数据变换,同时划分训练集和测试集。 - 模型设计
选择模型。 - 损失函数和优化方案设计
设定损失函数和优化方法,以及对应的超参数(当然可以使用sklearn这样的机器学习库中模型自带的损失函数和优化器)。 - 前向传播
用模型去拟合训练集数据, - 反向传播
- 更新参数
- 模型表现
在验证集/测试集上计算模型表现。
深度学习在实现上的特殊性
- 样本量大,需要分批加载
由于深度学习所需的样本量很大,一次加载全部数据运行可能会超出内存容量而无法实现;同时还有批(batch)训练等提高模型表现的策略,需要每次训练读取固定数量的样本送入模型中训练。 - 逐层、模块化搭建网络(卷积层、全连接层、LSTM等)
深度神经网络往往需要“逐层”搭建,或者预先定义好可以实现特定功能的模块,再把这些模块组装起来。 - 多样化的损失函数和优化器设计
由于模型设定的灵活性,因此损失函数和优化器要能够保证反向传播能够在用户自行定义的模型结构上实现 - GPU的使用
需要把模型和数据“放到”GPU上去做运算,同时还需要保证损失函数和优化器能够在GPU上工作。如果使用多张GPU进行训练,还需要考虑模型和数据分配、整合的问题。 - 各个模块之间的配合
深度学习中训练和验证过程最大的特点在于读入数据是按批的,每次读入一个批次的数据,放入GPU中训练,然后将损失函数反向传播回网络最前面的层,同时使用优化器调整网络参数。这里会涉及到各个模块配合的问题。训练/验证后还需要根据设定好的指标计算模型表现。
pytorch深度学习模块
将PyTorch完成深度学习的步骤拆解为几个主要模块,实际使用根据自身需求修改对应模块即可,深度学习->搭积木。
一、 基本配置
首先导入必要的包
1 | import os |
配置训练环境和超参数
1 | # 配置GPU,这里有两种方式 |
二、 数据读入
有两种方式:
- 下载并使用PyTorch提供的内置数据集
只适用于常见的数据集,如MNIST,CIFAR10等,PyTorch官方提供了数据下载。这种方式往往适用于快速测试方法(比如测试下某个idea在MNIST数据集上是否有效)1
2
3
4
5
6
7
8
9# 首先设置数据变换
from torchvision import transforms
image_size = 28
data_transform = transforms.Compose([
transforms.ToPILImage(), # 这一步取决于后续的数据读取方式,如果使用内置数据集则不需要
transforms.Resize(image_size),
transforms.ToTensor()
])1
2
3
4
5## 读取方式一:使用torchvision自带数据集,下载可能需要一段时间
from torchvision import datasets
train_data = datasets.FashionMNIST(root='./', train=True, download=True, transform=data_transform)
test_data = datasets.FashionMNIST(root='./', train=False, download=True, transform=data_transform) - 从网站下载以csv格式存储的数据,读入并转成预期的格式
需要自己构建Dataset,这对于PyTorch应用于自己的工作中十分重要,同时,还需要对数据进行必要的变换,比如说需要将图片统一为一致的大小,以便后续能够输入网络训练;需要将数据格式转为Tensor类,等等。PyTorch数据读入是通过Dataset+DataLoader的方式完成的,Dataset定义好数据的格式和数据变换形式,DataLoader用iterative的方式不断读入批次数据。我们可以定义自己的Dataset类来实现灵活的数据读取,定义的类需要继承PyTorch自身的Dataset类。主要包含三个函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26## 读取方式二:读入csv格式的数据,自行构建Dataset类
# csv数据下载链接:https://www.kaggle.com/zalando-research/fashionmnist
class FMDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.transform = transform
self.images = df.iloc[:,1:].values.astype(np.uint8)
self.labels = df.iloc[:, 0].values
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx].reshape(28,28,1) # 1是单一通道
label = int(self.labels[idx])
if self.transform is not None:
image = self.transform(image)
else:
image = torch.tensor(image/255., dtype=torch.float) # image/255 把数值归一化
label = torch.tensor(label, dtype=torch.long)
return image, label
train_df = pd.read_csv("./fashion-mnist_train.csv")
test_df = pd.read_csv("./fashion-mnist_test.csv")
train_data = FMDataset(train_df, data_transform)
test_data = FMDataset(test_df, data_transform) - _init_: 用于向类中传入外部参数,同时定义样本集
- _getitem_: 用于逐个读取样本集合中的元素,可以进行一定的变换,并将返回训练/验证所需的数据
- _len_: 用于返回数据集的样本数
在构建训练和测试数据集完成后,需要定义DataLoader类,以便在训练和测试时加载数据:读入后,我们可以做一些数据可视化操作,主要是验证我们读入的数据是否正确:1
2train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=num_workers)1
2
3
4import matplotlib.pyplot as plt
image, label = next(iter(train_loader))
print(image.shape, label.shape)
plt.imshow(image[0][0], cmap="gray")

三、 模型构建
我们这里的任务是对10个类别的“时装”图像进行分类,FashionMNIST数据集中包含已经预先划分好的训练集和测试集,其中训练集共60,000张图像,测试集共10,000张图像。每张图像均为单通道黑白图像,大小为32*32pixel,分属10个类别。由于任务较为简单,这里我们手搭一个CNN,而不考虑当下各种模型的复杂结构,模型构建完成后,将模型放到GPU上用于训练。
Module 类是nn模块里提供的一个模型构造类,是所有神经⽹网络模块的基类,我们可以继承它来定义我们想要的模型。
1 | class Net(nn.Module): |
torch.nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros',
device=None,
dtype=None)
torch.nn.MaxPool2d(
kernel_size,
stride=None,
padding=0,
dilation=1,
return_indices=False,
ceil_mode=False)
$d_{out} =(d_{in}−dilation∗(kernelsize−1)−1+2∗padding)/stride+1)$
下面再举一个其他模型MLP:
继承Module类构造多层感知机,这里定义的MLP类重载了Module类的init函数和forward函数。它们分别用于创建模型参数和定义前向计算。前向计算也即正向传播。系统将通过⾃动求梯度⽽自动⽣成反向传播所需的 backward 函数。
1 | import torch |
我们可以实例化 MLP 类得到模型变量 net 。下⾯的代码初始化 net 并传入输⼊数据 X 做一次前向计算。其中, net(X) 会调用 MLP 继承⾃自 Module 类的 call 函数,这个函数将调⽤用 MLP 类定义的forward 函数来完成前向计算。
1 | X = torch.rand(2,784) |
注意,这里并没有将 Module 类命名为 Layer (层)或者 Model (模型)之类的名字,这是因为该类是一个可供⾃由组建的部件。它的子类既可以是⼀个层(如PyTorch提供的 Linear 类),⼜可以是一个模型(如这里定义的 MLP 类),或者是模型的⼀个部分。
下面介绍一些神经网络中常见的层:
深度学习的一个魅力在于神经网络中各式各样的层,例如全连接层、卷积层、池化层与循环层等等。虽然PyTorch提供了⼤量常用的层,但有时候我们依然希望⾃定义层。
- 不含模型参数的层
下⾯构造的 MyLayer 类通过继承 Module 类自定义了一个将输入减掉均值后输出的层,并将层的计算定义在了 forward 函数里。这个层里不含模型参数。1
2
3
4
5
6
7
8
9
10
11import torch
from torch import nn
class MyLayer(nn.Module):
def __init__(self, **kwargs):
super(MyLayer, self).__init__(**kwargs)
def forward(self, x):
return x - x.mean()
# 测试,实例化该层,然后做前向计算
layer = MyLayer()
layer(torch.tensor([1, 2, 3, 4, 5], dtype=torch.float)) - 含模型参数的层
自定义含模型参数的自定义层,其中的模型参数可以通过训练学出。Parameter 类其实是 Tensor 的子类,如果一个 Tensor 是 Parameter ,那么它会⾃动被添加到模型的参数列表里。所以在⾃定义含模型参数的层时,我们应该将参数定义成 Parameter ,除了直接定义成 Parameter 类外,还可以使⽤ ParameterList 和 ParameterDict 分别定义参数的列表和字典。下面给出常见的神经网络的一些层,比如卷积层、池化层,以及较为基础的AlexNet,LeNet等。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class MyListDense(nn.Module):
def __init__(self):
super(MyListDense, self).__init__()
self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)])
self.params.append(nn.Parameter(torch.randn(4, 1)))
def forward(self, x):
for i in range(len(self.params)):
x = torch.mm(x, self.params[i]) # torch.mm矩阵相乘,两个二维张量相乘
return x
net = MyListDense()
print(net)
class MyDictDense(nn.Module):
def __init__(self):
super(MyDictDense, self).__init__()
self.params = nn.ParameterDict({
'linear1': nn.Parameter(torch.randn(4, 4)),
'linear2': nn.Parameter(torch.randn(4, 1))
})
self.params.update({'linear3': nn.Parameter(torch.randn(4, 2))}) # 新增
def forward(self, x, choice='linear1'):
return torch.mm(x, self.params[choice])
net = MyDictDense()
print(net) - 二维卷积层
二维卷积层将输入和卷积核做互相关运算,并加上一个标量偏差来得到输出。卷积层的模型参数包括了卷积核和标量偏差。在训练模型的时候,通常我们先对卷积核随机初始化,然后不断迭代卷积核和偏差。下面的例子里我们创建一个⾼和宽为3的二维卷积层,然后设输⼊高和宽两侧的填充数分别为1。给定一个高和宽为8的输入,我们发现输出的高和宽也是8。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import torch
from torch import nn
# 卷积运算(二维互相关)
def corr2d(X, K):
h, w = K.shape
X, K = X.float(), K.float()
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
return Y
# 二维卷积层
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias当卷积核的高和宽不同时,我们也可以通过设置高和宽上不同的填充数使输出和输入具有相同的高和宽。填充可以增加输出的高和宽。这常用来使输出与输入具有相同的高和宽。步幅可以减小输出的高和宽,例如输出的高和宽仅为输入的高和宽的 ( 为大于1的整数)。1
2
3
4
5
6
7
8
9
10
11
12
13# 定义一个函数来计算卷积层。它对输入和输出做相应的升维和降维
def comp_conv2d(conv2d, X):
# (1, 1)代表批量大小和通道数
X = X.view((1, 1) + X.shape) # 加上两个维度
Y = conv2d(X)
return Y.view(Y.shape[2:]) # 排除不关心的前两维:批量和通道
# 注意这里是两侧分别填充1⾏或列,所以在两侧一共填充2⾏或列
conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3,padding=1)
X = torch.rand(8, 8)
comp_conv2d(conv2d, X).shape1
2
3# 使用高为5、宽为3的卷积核。在⾼和宽两侧的填充数分别为2和1,-5+2*2=-3+2*1
conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(5, 3), padding=(2, 1))
comp_conv2d(conv2d, X).shape - 池化层
池化层每次对输入数据的一个固定形状窗口(⼜称池化窗口)中的元素计算输出。不同于卷积层里计算输⼊和核的互相关性,池化层直接计算池化窗口内元素的最大值或者平均值。该运算也分别叫做最大池化或平均池化。在二维最⼤池化中,池化窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输⼊数组上滑动。当池化窗口滑动到某⼀位置时,窗口中的输入子数组的最大值即输出数组中相应位置的元素。下面把池化层的前向计算实现在pool2d函数里。我们可以使用torch.nn包来构建神经网络。我们已经介绍了autograd包,nn包则依赖于autograd包来定义模型并对它们求导。一个nn.Module包含各个层和一个forward(input)方法,该方法返回output。1
2
3
4
5
6
7
8
9
10def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y - LeNet模型示例
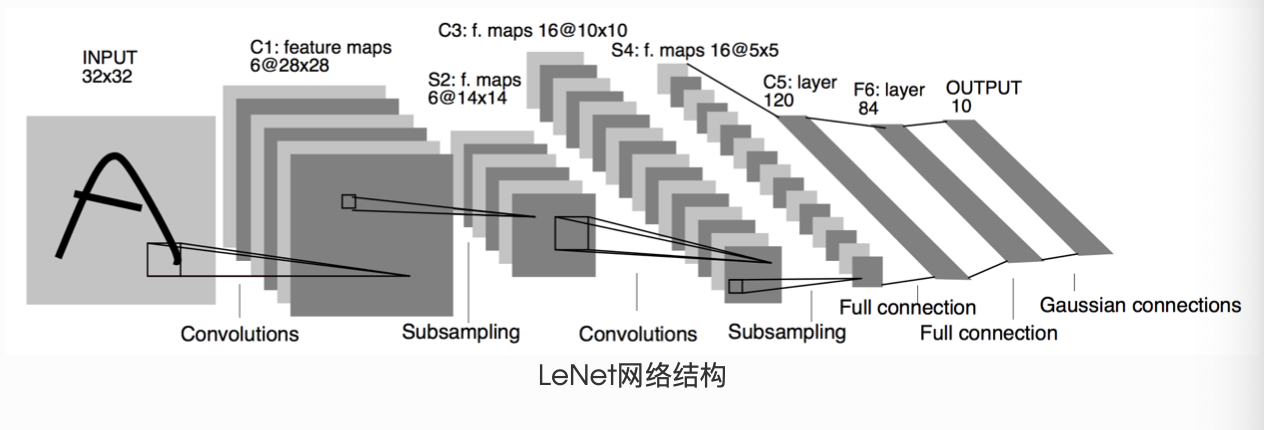
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 输入图像channel:1;输出channel:6;5x5卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 2x2 Max pooling
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 如果是方阵,则可以只使用一个数字进行定义
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 除去批处理维度的其他所有维度
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)Net( (conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1)) (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear(in_features=400, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True) )
我们只需要定义 forward 函数,backward函数会在使用autograd时自动定义,backward函数用来计算导数。我们可以在 forward 函数中使用任何针对张量的操作和计算。一个模型的可学习参数可以通过net.parameters()返回。
1 | params = list(net.parameters()) |
尝试随机输入
1 | input = torch.randn(1, 1, 32, 32) |
torch.nn只支持小批量处理 (mini-batches)。整个 torch.nn 包只支持小批量样本的输入,不支持单个样本的输入。比如,nn.Conv2d 接受一个4维的张量,即nSamples x nChannels x Height x Width 如果是一个单独的样本,只需要使用input.unsqueeze(0) 来添加一个“假的”批大小维度。
torch.Tensor - 一个多维数组,支持诸如backward()等的自动求导操作,同时也保存了张量的梯度。
nn.Module - 神经网络模块。是一种方便封装参数的方式,具有将参数移动到GPU、导出、加载等功能。
nn.Parameter - 张量的一种,当它作为一个属性分配给一个Module时,它会被自动注册为一个参数。
autograd.Function - 实现了自动求导前向和反向传播的定义,每个Tensor至少创建一个Function节点,该节点连接到创建Tensor的函数并对其历史进行编码。
- AlexNet模型示例
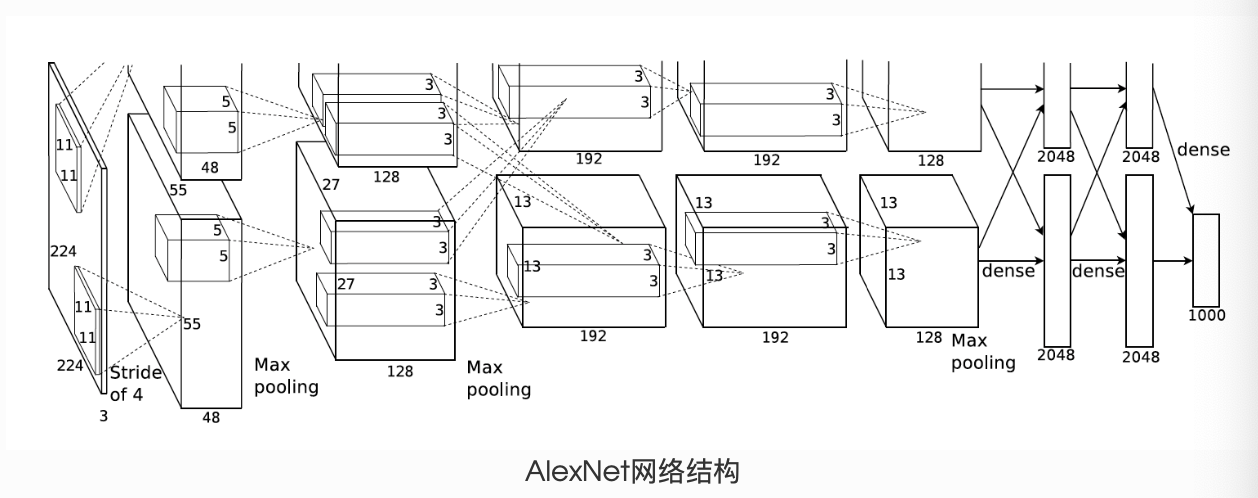
1 | class AlexNet(nn.Module): |
AlexNet(
(conv): Sequential(
(0): Conv2d(1, 96, kernel_size=(11, 11), stride=(4, 4))
(1): ReLU()
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU()
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU()
(8): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU()
(10): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU()
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=6400, out_features=4096, bias=True)
(1): ReLU()
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU()
(5): Dropout(p=0.5)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
四、 模型初始化
- torch.nn.init使用
通常使用isinstance来进行判断模块查看不同初始化参数1
2
3
4
5
6
7
8import torch
import torch.nn as nn
conv = nn.Conv2d(1,3,3)
linear = nn.Linear(10,1)
isinstance(conv,nn.Conv2d)
isinstance(linear,nn.Conv2d)对不同类型层进行初始化1
2
3
4# 查看随机初始化的conv参数
conv.weight.data
# 查看linear的参数
linear.weight.data1
2
3
4
5
6# 对conv进行kaiming初始化
torch.nn.init.kaiming_normal_(conv.weight.data)
conv.weight.data
# 对linear进行常数初始化
torch.nn.init.constant_(linear.weight.data,0.3)
linear.weight.data - 初始化函数的封装
人们常常将各种初始化方法定义为一个initialize_weights()的函数并在模型初始后进行使用。这段代码流程是遍历当前模型的每一层,然后判断各层属于什么类型,然后根据不同类型层,设定不同的权值初始化方法。我们可以通过下面的例程进行一个简短的演示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def initialize_weights(self):
for m in self.modules():
# 判断是否属于Conv2d
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight.data)
# 判断是否有偏置
if m.bias is not None:
torch.nn.init.constant_(m.bias.data,0.3)
elif isinstance(m, nn.Linear):
torch.nn.init.normal_(m.weight.data, 0.1)
if m.bias is not None:
torch.nn.init.zeros_(m.bias.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zeros_()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# 模型的定义
class MLP(nn.Module):
# 声明带有模型参数的层,这里声明了两个全连接层
def __init__(self, **kwargs):
# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Conv2d(1,1,3)
self.act = nn.ReLU()
self.output = nn.Linear(10,1)
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
def forward(self, x):
o = self.act(self.hidden(x))
return self.output(o)
mlp = MLP()
print(list(mlp.parameters()))
print("-------初始化-------")
initialize_weights(mlp)
print(list(mlp.parameters()))[Parameter containing: tensor([[[[ 0.2103, -0.1679, 0.1757], [-0.0647, -0.0136, -0.0410], [ 0.1371, -0.1738, -0.0850]]]], requires_grad=True), Parameter containing: tensor([0.2507], requires_grad=True), Parameter containing: tensor([[ 0.2790, -0.1247, 0.2762, 0.1149, -0.2121, -0.3022, -0.1859, 0.2983, -0.0757, -0.2868]], requires_grad=True), Parameter containing: tensor([-0.0905], requires_grad=True)] "-------初始化-------" [Parameter containing: tensor([[[[-0.3196, -0.0204, -0.5784], [ 0.2660, 0.2242, -0.4198], [-0.0952, 0.6033, -0.8108]]]], requires_grad=True), Parameter containing: tensor([0.3000], requires_grad=True), Parameter containing: tensor([[ 0.7542, 0.5796, 2.2963, -0.1814, -0.9627, 1.9044, 0.4763, 1.2077, 0.8583, 1.9494]], requires_grad=True), Parameter containing: tensor([0.], requires_grad=True)]
五、 损失函数
这里使用torch.nn模块自带的CrossEntropy损失,PyTorch会自动把整数型的label转为one-hot型,用于计算CE loss,这里需要确保label是从0开始的,同时模型不加softmax层(使用logits计算),这也说明了PyTorch训练中各个部分不是独立的,需要通盘考虑。
1 | criterion = nn.CrossEntropyLoss() |
1. 二分类交叉熵损失函数
1 | torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean') |
功能:计算二分类任务时的交叉熵(Cross Entropy)函数。在二分类中,label是{0,1}。对于进入交叉熵函数的input为概率分布的形式。一般来说,input为sigmoid激活层的输出,或者softmax的输出。
主要参数:weight:每个类别的loss设置权值size_average:数据为bool,为True时,返回的loss为平均值;为False时,返回的各样本的loss之和。reduce:数据类型为bool,为True时,loss的返回是标量。
计算公式如下:

1 | m = nn.Sigmoid() |
BCELoss损失函数的计算结果为 tensor(0.5732, grad_fn=<BinaryCrossEntropyBackward>)
2. 交叉熵损失函数
1 | torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean') |
功能:计算交叉熵函数
主要参数:weight:每个类别的loss设置权值。size_average:数据为bool,为True时,返回的loss为平均值;为False时,返回的各样本的loss之和。ignore_index:忽略某个类的损失函数。reduce:数据类型为bool,为True时,loss的返回是标量。
计算公式如下:
$
\operatorname{loss}(x, \text { class })=-\log \left(\frac{\exp (x[\text { class }])}{\sum_{j} \exp (x[j])}\right)=-x[\text { class }]+\log \left(\sum_{j} \exp (x[j])\right)
$
1 | loss = nn.CrossEntropyLoss() |
tensor(2.0115, grad_fn=<NllLossBackward>)
3. L1损失函数
1 | torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean') |
功能: 计算输出y和真实标签target之间的差值的绝对值。reduction参数决定了计算模式。有三种计算模式可选:none:逐个元素计算。sum:所有元素求和,返回标量。mean:加权平均,返回标量。如果选择none,那么返回的结果是和输入元素相同尺寸的。默认计算方式是求平均。
计算公式如下:
$
L_{n} = |x_{n}-y_{n}|
$
1 | loss = nn.L1Loss() |
L1损失函数的计算结果为 tensor(1.5729, grad_fn=<L1LossBackward>)
4. MSE损失函数
1 | torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean') |
功能: 计算输出y和真实标签target之差的平方。
和L1Loss一样,MSELoss损失函数中,reduction参数决定了计算模式。有三种计算模式可选:none:逐个元素计算。sum:所有元素求和,返回标量。默认计算方式是求平均。
计算公式如下:
$
l_{n}=\left(x_{n}-y_{n}\right)^{2}
$
1 | loss = nn.MSELoss() |
MSE损失函数的计算结果为 tensor(1.6968, grad_fn=<MseLossBackward>)
5. 平滑L1 (Smooth L1)损失函数
1 | torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean', beta=1.0) |
功能: L1的平滑输出,其功能是减轻离群点带来的影响
reduction参数决定了计算模式。有三种计算模式可选:none:逐个元素计算。sum:所有元素求和,返回标量。默认计算方式是求平均。
提醒: 之后的损失函数中,关于reduction 这个参数依旧会存在。所以,之后就不再单独说明。
计算公式如下:
$
\operatorname{loss}(x, y)=\frac{1}{n} \sum_{i=1}^{n} z_{i}
$
其中,

1 | loss = nn.SmoothL1Loss() |
SmoothL1Loss损失函数的计算结果为 tensor(0.7808, grad_fn=<SmoothL1LossBackward>)
平滑L1与L1的对比
这里我们通过可视化两种损失函数曲线来对比平滑L1和L1两种损失函数的区别。
1 | inputs = torch.linspace(-10, 10, steps=5000) |
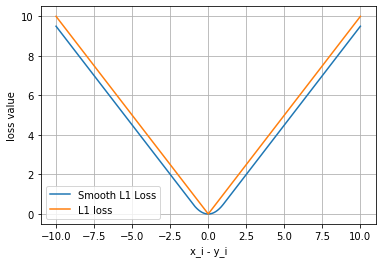
可以看出,对于smoothL1来说,在 0 这个尖端处,过渡更为平滑。
6. 目标泊松分布的负对数似然损失
1 | torch.nn.PoissonNLLLoss(log_input=True, full=False, size_average=None, eps=1e-08, reduce=None, reduction='mean') |
功能: 泊松分布的负对数似然损失函数
主要参数:log_input:输入是否为对数形式,决定计算公式。full:计算所有 loss,默认为 False。eps:修正项,避免 input 为 0 时,log(input) 为 nan 的情况。
数学公式:
- 当参数
log_input=True:
$
\operatorname{loss}\left(x_{n}, y_{n}\right)=e^{x_{n}}-x_{n} \cdot y_{n}
$ - 当参数
log_input=False:
$
\operatorname{loss}\left(x_{n}, y_{n}\right)=x_{n}-y_{n} \cdot \log \left(x_{n}+\text { eps }\right)
$
1 | loss = nn.PoissonNLLLoss() |
PoissonNLLLoss损失函数的计算结果为 tensor(0.7358, grad_fn=<MeanBackward0>)
7. KL散度
1 | torch.nn.KLDivLoss(size_average=None, reduce=None, reduction='mean', log_target=False) |
功能: 计算KL散度,也就是计算相对熵。用于连续分布的距离度量,并且对离散采用的连续输出空间分布进行回归通常很有用。
主要参数:reduction:计算模式,可为 none/sum/mean/batchmean。
none:逐个元素计算。
sum:所有元素求和,返回标量。
mean:加权平均,返回标量。
batchmean:batchsize 维度求平均值。
计算公式:

1 | inputs = torch.tensor([[0.5, 0.3, 0.2], [0.2, 0.3, 0.5]]) |
KLDivLoss损失函数的计算结果为 tensor(-0.3335)
8. MarginRankingLoss
1 | torch.nn.MarginRankingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean') |
功能: 计算两个向量之间的相似度,用于排序任务。该方法用于计算两组数据之间的差异。
主要参数:margin:边界值,$x_{1}$ 与$x_{2}$ 之间的差异值。reduction:计算模式,可为 none/sum/mean。
计算公式:
$
\operatorname{loss}(x 1, x 2, y)=\max (0,-y *(x 1-x 2)+\operatorname{margin})
$
1 | loss = nn.MarginRankingLoss() |
MarginRankingLoss损失函数的计算结果为 tensor(0.7740, grad_fn=<MeanBackward0>)
9. 多标签边界损失函数
1 | torch.nn.MultiLabelMarginLoss(size_average=None, reduce=None, reduction='mean') |
功能: 对于多标签分类问题计算损失函数。
主要参数:reduction:计算模式,可为 none/sum/mean。
计算公式:
$
\operatorname{loss}(x, y)=\sum_{i j} \frac{\max (0,1-x[y[j]]-x[i])}{x \cdot \operatorname{size}(0)}
$
$
\begin{array}{l}
\text { 其中, } i=0, \ldots, x \cdot \operatorname{size}(0), j=0, \ldots, y \cdot \operatorname{size}(0), \text { 对于所有的 } i \text { 和 } j \text {, 都有 } y[j] \geq 0 \text { 并且 }\
i \neq y[j]
\end{array}
$
1 | loss = nn.MultiLabelMarginLoss() |
MultiLabelMarginLoss损失函数的计算结果为 tensor(0.4500)
10. 二分类损失函数
1 | torch.nn.SoftMarginLoss(size_average=None, reduce=None, reduction='mean')torch.nn.(size_average=None, reduce=None, reduction='mean') |
功能: 计算二分类的 logistic 损失。
主要参数:reduction:计算模式,可为 none/sum/mean。
计算公式:
$
\operatorname{loss}(x, y)=\sum_{i} \frac{\log (1+\exp (-y[i] \cdot x[i]))}{x \cdot \operatorname{nelement}()}
$
$
\text { 其中, } x . \text { nelement() 为输入 } x \text { 中的样本个数。注意这里 } y \text { 也有 } 1 \text { 和 }-1 \text { 两种模式。 }
$
1 | inputs = torch.tensor([[0.3, 0.7], [0.5, 0.5]]) # 两个样本,两个神经元 |
SoftMarginLoss损失函数的计算结果为 tensor(0.6764)
11. 多分类的折页损失
1 | torch.nn.MultiMarginLoss(p=1, margin=1.0, weight=None, size_average=None, reduce=None, reduction='mean') |
功能: 计算多分类的折页损失
主要参数:reduction:计算模式,可为 none/sum/mean。p:可选 1 或 2。weight:各类别的 loss 设置权值。margin:边界值
计算公式:
$
\operatorname{loss}(x, y)=\frac{\sum_{i} \max (0, \operatorname{margin}-x[y]+x[i])^{p}}{x \cdot \operatorname{size}(0)}
$
$
\begin{array}{l}
\text { 其中, } x \in{0, \ldots, x \cdot \operatorname{size}(0)-1}, y \in{0, \ldots, y \cdot \operatorname{size}(0)-1} \text {, 并且对于所有的 } i \text { 和 } j \text {, }\
\text { 都有 } 0 \leq y[j] \leq x \cdot \operatorname{size}(0)-1, \text { 以及 } i \neq y[j] \text { 。 }
\end{array}
$
1 | inputs = torch.tensor([[0.3, 0.7], [0.5, 0.5]]) |
MultiMarginLoss损失函数的计算结果为 tensor(0.6000)
12. 三元组损失
1 | torch.nn.TripletMarginLoss(margin=1.0, p=2.0, eps=1e-06, swap=False, size_average=None, reduce=None, reduction='mean') |
功能: 计算三元组损失。
三元组: 这是一种数据的存储或者使用格式。<实体1,关系,实体2>。在项目中,也可以表示为< anchor, positive examples , negative examples>
在这个损失函数中,我们希望去anchor的距离更接近positive examples,而远离negative examples
主要参数:reduction:计算模式,可为 none/sum/mean。p:可选 1 或 2。margin:边界值
计算公式:

1 | triplet_loss = nn.TripletMarginLoss(margin=1.0, p=2) |
TripletMarginLoss损失函数的计算结果为 tensor(1.1667, grad_fn=<MeanBackward0>)
13. HingEmbeddingLoss
1 | torch.nn.HingeEmbeddingLoss(margin=1.0, size_average=None, reduce=None, reduction='mean') |
功能: 对输出的embedding结果做Hing损失计算
主要参数:reduction:计算模式,可为 none/sum/mean。margin:边界值
计算公式:

注意事项: 输入x应为两个输入之差的绝对值。
可以这样理解,让个输出的是正例yn=1,那么loss就是x,如果输出的是负例y=-1,那么输出的loss就是要做一个比较。
1 | loss_f = nn.HingeEmbeddingLoss() |
HingEmbeddingLoss损失函数的计算结果为 tensor(0.7667)
14. 余弦相似度
1 | torch.nn.CosineEmbeddingLoss(margin=0.0, size_average=None, reduce=None, reduction='mean') |
功能: 对两个向量做余弦相似度
主要参数:reduction:计算模式,可为 none/sum/mean。margin:可取值[-1,1] ,推荐为[0,0.5] 。
计算公式:

这个损失函数应该是最广为人知的。对于两个向量,做余弦相似度。将余弦相似度作为一个距离的计算方式,如果两个向量的距离近,则损失函数值小,反之亦然。
1 | loss_f = nn.CosineEmbeddingLoss() |
CosineEmbeddingLoss损失函数的计算结果为 tensor(0.5000)
15.CTC损失函数
1 | torch.nn.CTCLoss(blank=0, reduction='mean', zero_infinity=False) |
功能: 用于解决时序类数据的分类
计算连续时间序列和目标序列之间的损失。CTCLoss对输入和目标的可能排列的概率进行求和,产生一个损失值,这个损失值对每个输入节点来说是可分的。输入与目标的对齐方式被假定为 “多对一”,这就限制了目标序列的长度,使其必须是≤输入长度。
主要参数:reduction:计算模式,可为 none/sum/mean。blank:blank label。zero_infinity:无穷大的值或梯度值为
1 | # Target are to be padded |
CTCLoss损失函数的计算结果为 tensor(16.0885, grad_fn=<MeanBackward0>)
六、 优化器
这里使用Adam优化器
1 | optimizer = optim.Adam(model.parameters(), lr=0.001) |
Pytorch很人性化的给我们提供了一个优化器的库torch.optim,在这里面提供了十种优化器。
- torch.optim.ASGD
- torch.optim.Adadelta
- torch.optim.Adagrad
- torch.optim.Adam
- torch.optim.AdamW
- torch.optim.Adamax
- torch.optim.LBFGS
- torch.optim.RMSprop
- torch.optim.Rprop
- torch.optim.SGD
- torch.optim.SparseAdam
而以上这些优化算法均继承于Optimizer,下面我们先来看下所有优化器的基类Optimizer。定义如下:
1 | class Optimizer(object): |
Optimizer有三个属性:
defaults:存储的是优化器的超参数,例子如下:
1 | {'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False} |
state:参数的缓存,例子如下:
1 | defaultdict(<class 'dict'>, {tensor([[ 0.3864, -0.0131], |
param_groups:管理的参数组,是一个list,其中每个元素是一个字典,顺序是params,lr,momentum,dampening,weight_decay,nesterov,例子如下:
1 | [{'params': [tensor([[-0.1022, -1.6890],[-1.5116, -1.7846]], requires_grad=True)], 'lr': 1, 'momentum': 0, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}] |
Optimizer还有以下的方法:
zero_grad():清空所管理参数的梯度,PyTorch的特性是张量的梯度不自动清零,因此每次反向传播后都需要清空梯度。
1 | def zero_grad(self, set_to_none: bool = False): |
step():执行一步梯度更新,参数更新
1 | def step(self, closure): |
add_param_group():添加参数组
1 | def add_param_group(self, param_group): |
load_state_dict():加载状态参数字典,可以用来进行模型的断点续训练,继续上次的参数进行训练
1 | def load_state_dict(self, state_dict): |
state_dict():获取优化器当前状态信息字典
1 | def state_dict(self): |
实际操作
1 | import os |
输出结果
1 | # 进行更新前的数据,梯度 |
注意:
每个优化器都是一个类,我们一定要进行实例化才能使用,比如下方实现:
1
2
3
4
5class Net(nn.Moddule):
···
net = Net()
optim = torch.optim.SGD(net.parameters(),lr=lr)
optim.step()optimizer在一个神经网络的epoch中需要实现下面两个步骤:
- 梯度置零
- 梯度更新
1
2
3
4
5
6
7optimizer = torch.optim.SGD(net.parameters(), lr=1e-5)
for epoch in range(EPOCH):
...
optimizer.zero_grad() #梯度置零
loss = ... #计算loss
loss.backward() #BP反向传播
optimizer.step() #梯度更新
给网络不同的层赋予不同的优化器参数。
1
2
3
4
5
6
7
8
9
10from torch import optim
from torchvision.models import resnet18
net = resnet18()
optimizer = optim.SGD([
{'params':net.fc.parameters()},#fc的lr使用默认的1e-5
{'params':net.layer4[0].conv1.parameters(),'lr':1e-2}],lr=1e-5)
# 可以使用param_groups查看属性
实验
为了更好的了解优化器,对PyTorch中的优化器进行了一个小测试
数据生成:
1 | a = torch.linspace(-1, 1, 1000) |
数据分布曲线: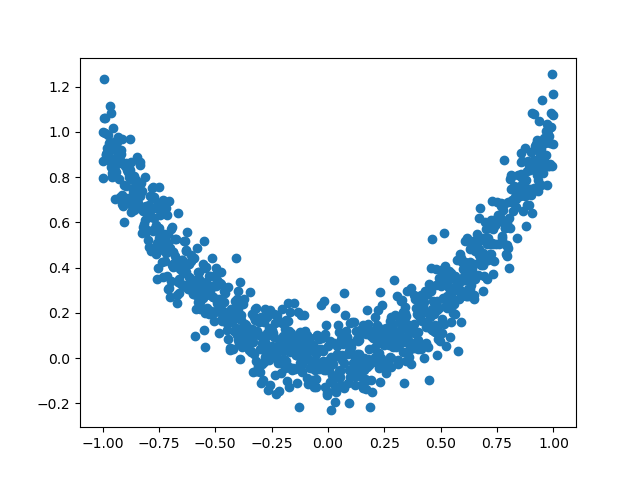
网络结构:
1 | class Net(nn.Module): |
下面这部分是测试图,纵坐标代表Loss,横坐标代表的是Step: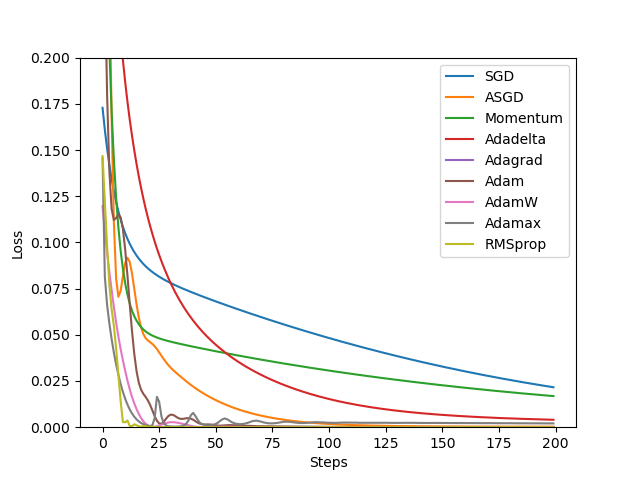
在上面的图片上,曲线下降的趋势和对应的steps代表了在这轮数据,模型下的收敛速度
注意:
优化器的选择是需要根据模型进行改变的,不存在绝对的好坏之分,我们需要多进行一些测试。
后续会添加SparseAdam,LBFGS这两个优化器的可视化结果
七、 训练与评估
关注两者的主要区别:
模型状态设置
是否需要初始化优化器
是否需要将loss传回到网络
是否需要每步更新optimizer
此外,对于测试或验证过程,可以计算分类准确率
1 | def train(epoch): |
1 | def val(epoch): |
1 | for epoch in range(1, epochs+1): |

八、 可视化
见后续专题
九、 保存模型
训练完成后,可以使用torch.save保存模型参数或者整个模型,也可以在训练过程中保存模型:
1 | save_path = "./FahionModel.pkl" |
参考资料
pytorch - 各个组件和实践

