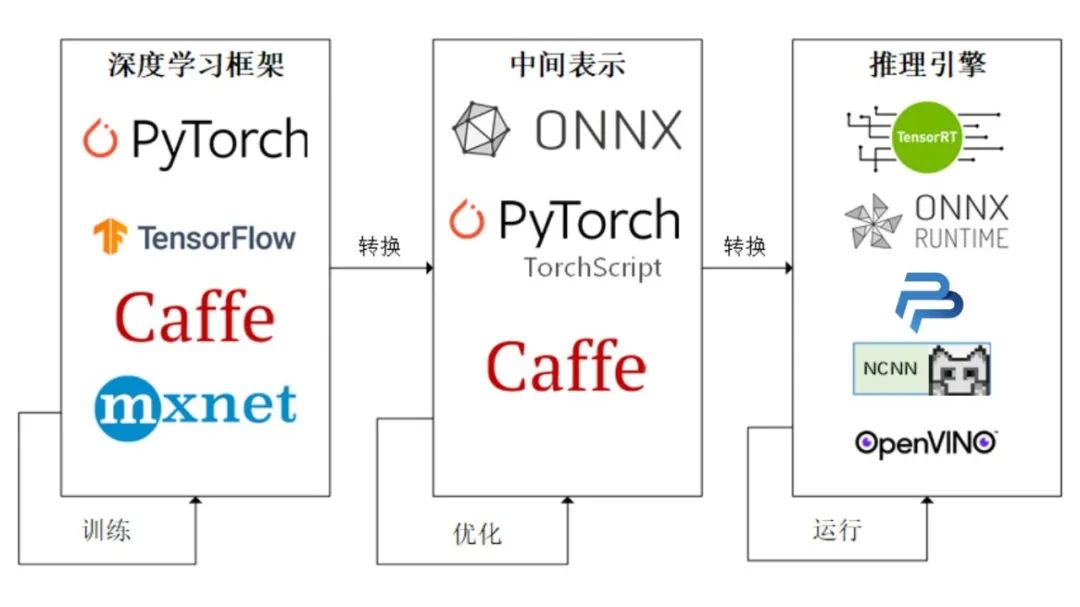
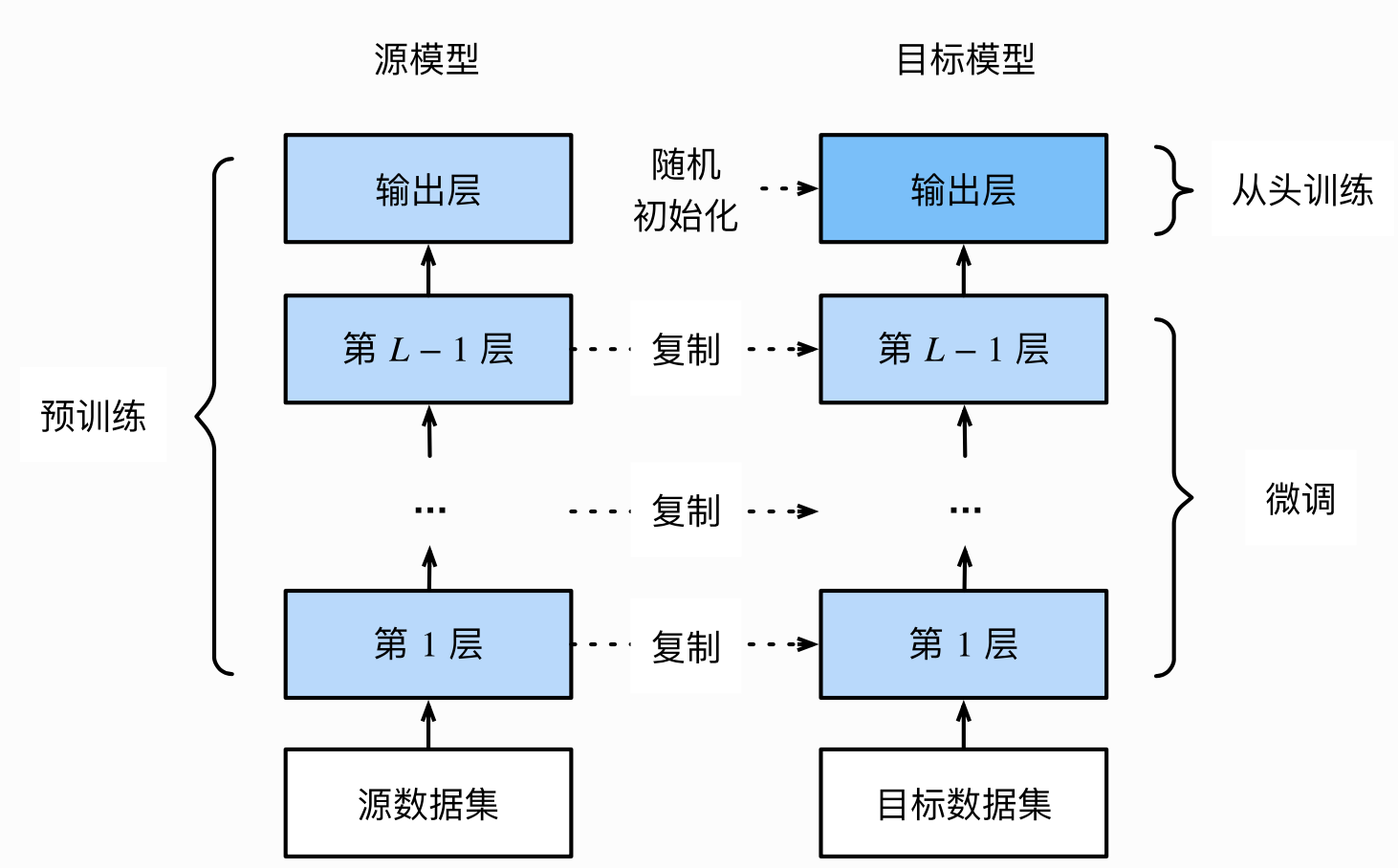
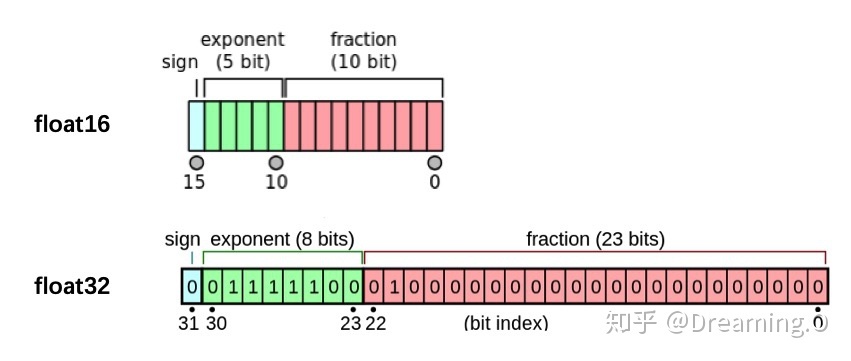
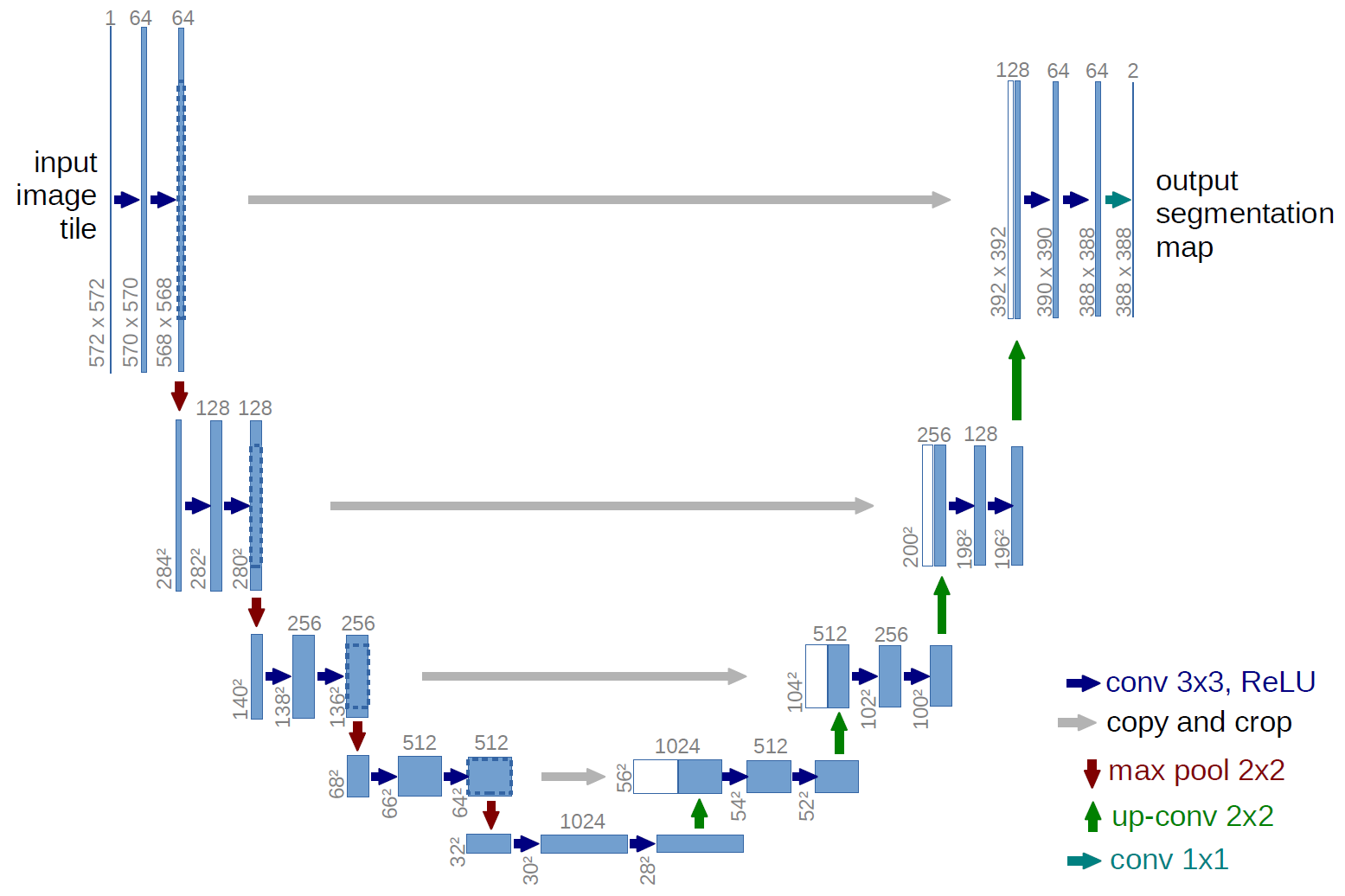
Field及其使用 Field是torchtext中定义数据类型以及转换为张量的指令。torchtext 认为一个样本是由多个字段(文本字段,标签字段)组成,不同的字段可能会有不同的处理方式,所以才会有 Field 抽象。定义Field对象是为了明确如何处理不同类型的数据,但具体的处理则是在Dataset中完成的。
from torchtext import data defget_dataset(csv_data, text_field, label_field, test=False): fields = [("id", None), # we won't be needing the id, so we pass in None as the field ("comment_text", text_field), ("toxic", label_field)] examples = []
if test: # 如果为测试集,则不加载label for text in tqdm(csv_data['comment_text']): examples.append(data.Example.fromlist([None, text, None], fields)) else: for text, label in tqdm(zip(csv_data['comment_text'], csv_data['toxic'])): examples.append(data.Example.fromlist([None, text, label], fields)) return examples, fields
词汇表(vocab) Word Embedding 的基本思想是收集一个比较大的语料库(尽量与所做的任务相关),在语料库中使用word2vec之类的方法构建词语到向量(或数字)的映射关系,之后将这一映射关系应用于当前的任务,将句子中的词语转为向量表示。在torchtext中可以使用Field自带的build_vocab函数完成词汇表构建。
# 同时对训练集和验证集进行迭代器的构建 train_iter, val_iter = BucketIterator.splits( (train, valid), # 构建数据集所需的数据集 batch_sizes=(8, 8), device=-1, # 如果使用gpu,此处将-1更换为GPU的编号 sort_key=lambda x: len(x.comment_text), # the BucketIterator needs to be told what function it should use to group the data. sort_within_batch=False )
import onnx # 我们可以使用异常处理的方法进行检验 try: # 当我们的模型不可用时,将会报出异常 onnx.checker.check_model(self.onnx_model) except onnx.checker.ValidationError as e: print("The model is invalid: %s"%e) else: # 模型可用时,将不会报出异常,并会输出“The model is valid!” print("The model is valid!")
for ftidx inrange(total_ft): if ftidx > 99: break ft = first_item[ftidx] plt.subplot(10, 10, ftidx+1) plt.axis('off') #plt.imshow(ft[ :, :].detach(),cmap='gray') plt.imshow(ft[ :, :].detach())
CNN class activation map可视化方法
1 2 3 4 5 6 7 8 9 10 11 12 13
import torch from torchvision.models import vgg11,resnet18,resnet101,resnext101_32x8d import matplotlib.pyplot as plt from PIL import Image import numpy as np
from pytorch_grad_cam import GradCAM,ScoreCAM,GradCAMPlusPlus,AblationCAM,XGradCAM,EigenCAM,FullGrad from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget from pytorch_grad_cam.utils.image import show_cam_on_image
import matplotlib.pyplot as plt import torchvision.models as models from flashtorch.utils import apply_transforms, load_image from flashtorch.saliency import Backprop
model = models.alexnet(pretrained=True) backprop = Backprop(model)
defforward(self,x): x = self.conv1(x) x = self.pool(x) x = self.conv2(x) x = self.pool(x) x = self.adaptive_pool(x) x = self.flatten(x) x = self.linear1(x) x = self.relu(x) x = self.linear2(x) y = self.sigmoid(x) return y
writer = SummaryWriter('./pytorch_tb') for i inrange(500): x = i y = x**2 writer.add_scalar("x", x, i) #日志中记录x在第step i 的值 writer.add_scalar("y", y, i) #日志中记录y在第step i 的值 writer.close()
writer1 = SummaryWriter('./pytorch_tb/x') writer2 = SummaryWriter('./pytorch_tb/y') for i inrange(500): x = i y = x*2 writer1.add_scalar("same", x, i) #日志中记录x在第step i 的值 writer2.add_scalar("same", y, i) #日志中记录y在第step i 的值 writer1.close() writer2.close()
TensorBoard参数分布可视化
1 2 3 4 5 6 7 8 9 10 11 12 13 14
import torch import numpy as np
# 创建正态分布的张量模拟参数矩阵 defnorm(mean, std): t = std * torch.randn((100, 20)) + mean return t writer = SummaryWriter('./pytorch_tb/') for step, mean inenumerate(range(-10, 10, 1)): w = norm(mean, 1) writer.add_histogram("w", w, step) writer.flush() writer.close()
defadjust_learning_rate(optimizer, epoch): lr = args.lr * (0.1 ** (epoch // 30)) # 学习率每30轮下降为原来的1/10 for param_group in optimizer.param_groups: param_group['lr'] = lr
# 对不同大小的图片进行处理 # 构建pipline seq = iaa.Sequential([ iaa.CropAndPad(percent=(-0.2, 0.2), pad_mode="edge"), # crop and pad images iaa.AddToHueAndSaturation((-60, 60)), # change their color iaa.ElasticTransformation(alpha=90, sigma=9), # water-like effect iaa.Cutout() # replace one squared area within the image by a constant intensity value ], random_order=True)
if __name__ == '__main__': set_seed(manual_seed) for epoch inrange(niters): train(model,lr,batch_size,num_workers,checkpoint_path) val(model,lr,batch_size,num_workers,checkpoint_path)
# if bilinear, use the normal convolutions to reduce the number of channels if bilinear: # 插值 self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True) self.conv = DoubleConv(in_channels, out_channels, in_channels // 2) else: self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2) self.conv = DoubleConv(in_channels, out_channels)
# 卷积运算(二维互相关) defcorr2d(X, K): h, w = K.shape X, K = X.float(), K.float() Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1)) for i inrange(Y.shape[0]): for j inrange(Y.shape[1]): Y[i, j] = (X[i: i + h, j: j + w] * K).sum() return Y
defforward(self, x): # 2x2 Max pooling x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # 如果是方阵,则可以只使用一个数字进行定义 x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, self.num_flat_features(x)) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x
defnum_flat_features(self, x): size = x.size()[1:] # 除去批处理维度的其他所有维度 num_features = 1 for s in size: num_features *= s return num_features
loss = nn.MultiLabelMarginLoss() x = torch.FloatTensor([[0.9, 0.2, 0.4, 0.8]]) # for target y, only consider labels 3 and 0, not after label -1 y = torch.LongTensor([[3, 0, -1, 1]])# 真实的分类是,第3类和第0类 output = loss(x, y) print('MultiLabelMarginLoss损失函数的计算结果为',output)
# Target are to be padded T = 50# Input sequence length C = 20# Number of classes (including blank) N = 16# Batch size S = 30# Target sequence length of longest target in batch (padding length) S_min = 10# Minimum target length, for demonstration purposes
# Initialize random batch of input vectors, for *size = (T,N,C) input = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()
# Initialize random batch of targets (0 = blank, 1:C = classes) target = torch.randint(low=1, high=C, size=(N, S), dtype=torch.long)
defzero_grad(self, set_to_none: bool = False): for group in self.param_groups: for p in group['params']: if p.grad isnotNone: #梯度不为空 if set_to_none: p.grad = None else: if p.grad.grad_fn isnotNone: p.grad.detach_() else: p.grad.requires_grad_(False) p.grad.zero_()# 梯度设置为0
defadd_param_group(self, param_group): assertisinstance(param_group, dict), "param group must be a dict" # 检查类型是否为tensor params = param_group['params'] ifisinstance(params, torch.Tensor): param_group['params'] = [params] elifisinstance(params, set): raise TypeError('optimizer parameters need to be organized in ordered collections, but ' 'the ordering of tensors in sets will change between runs. Please use a list instead.') else: param_group['params'] = list(params) for param in param_group['params']: ifnotisinstance(param, torch.Tensor): raise TypeError("optimizer can only optimize Tensors, " "but one of the params is " + torch.typename(param)) ifnot param.is_leaf: raise ValueError("can't optimize a non-leaf Tensor")
for name, default in self.defaults.items(): if default is required and name notin param_group: raise ValueError("parameter group didn't specify a value of required optimization parameter " + name) else: param_group.setdefault(name, default)
params = param_group['params'] iflen(params) != len(set(params)): warnings.warn("optimizer contains a parameter group with duplicate parameters; " "in future, this will cause an error; " "see github.com/pytorch/pytorch/issues/40967 for more information", stacklevel=3) # 上面好像都在进行一些类的检测,报Warning和Error param_set = set() for group in self.param_groups: param_set.update(set(group['params']))
ifnot param_set.isdisjoint(set(param_group['params'])): raise ValueError("some parameters appear in more than one parameter group") # 添加参数 self.param_groups.append(param_group)
defload_state_dict(self, state_dict): r"""Loads the optimizer state. Arguments: state_dict (dict): optimizer state. Should be an object returned from a call to :meth:`state_dict`. """ # deepcopy, to be consistent with module API state_dict = deepcopy(state_dict) # Validate the state_dict groups = self.param_groups saved_groups = state_dict['param_groups']
iflen(groups) != len(saved_groups): raise ValueError("loaded state dict has a different number of " "parameter groups") param_lens = (len(g['params']) for g in groups) saved_lens = (len(g['params']) for g in saved_groups) ifany(p_len != s_len for p_len, s_len inzip(param_lens, saved_lens)): raise ValueError("loaded state dict contains a parameter group " "that doesn't match the size of optimizer's group")
# Update the state id_map = {old_id: p for old_id, p in zip(chain.from_iterable((g['params'] for g in saved_groups)), chain.from_iterable((g['params'] for g in groups)))}
defcast(param, value): r"""Make a deep copy of value, casting all tensors to device of param.""" .....
# Copy state assigned to params (and cast tensors to appropriate types). # State that is not assigned to params is copied as is (needed for # backward compatibility). state = defaultdict(dict) for k, v in state_dict['state'].items(): if k in id_map: param = id_map[k] state[param] = cast(param, v) else: state[k] = v
# Update parameter groups, setting their 'params' value defupdate_group(group, new_group): ... param_groups = [ update_group(g, ng) for g, ng inzip(groups, saved_groups)] self.__setstate__({'state': state, 'param_groups': param_groups})
defstate_dict(self): r"""Returns the state of the optimizer as a :class:`dict`. It contains two entries: * state - a dict holding current optimization state. Its content differs between optimizer classes. * param_groups - a dict containing all parameter groups """ # Save order indices instead of Tensors param_mappings = {} start_index = 0
defpack_group(group): ...... param_groups = [pack_group(g) for g in self.param_groups] # Remap state to use order indices as keys packed_state = {(param_mappings[id(k)] ifisinstance(k, torch.Tensor) else k): v for k, v in self.state.items()} return { 'state': packed_state, 'param_groups': param_groups, }
# 进行更新前的数据,梯度 The data of weight before step: tensor([[-0.3077, -0.1808], [-0.7462, -1.5556]]) The grad of weight before step: tensor([[1., 1.], [1., 1.]]) # 进行更新后的数据,梯度 The data of weight after step: tensor([[-0.4077, -0.2808], [-0.8462, -1.6556]]) The grad of weight after step: tensor([[1., 1.], [1., 1.]]) # 进行梯度清零的梯度 The grad of weight after optimizer.zero_grad(): tensor([[0., 0.], [0., 0.]]) # 输出信息 optimizer.params_group is [{'params': [tensor([[-0.4077, -0.2808], [-0.8462, -1.6556]], requires_grad=True)], 'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False}]
注:数据在GPU和CPU之间进行传递时会比较耗时,我们应当尽量避免数据的切换。GPU运算很快,但是在使用简单的操作时,我们应该尽量使用CPU去完成。当我们的服务器上有多个GPU,我们应该指明我们使用的GPU是哪一块,如果我们不设置的话,tensor.cuda()方法会默认将tensor保存到第一块GPU上,等价于tensor.cuda(0),这将会导致爆出out of memory的错误。我们可以通过以下两种方式继续设置。
Word2vec is a software package that actually includes :
2 algorithms: continuous bag-of-words (CBOW) and skip-gram.
CBOW aims to predict a center word from the surrounding context in terms of word vectors. Skip-gram does the opposite, and predicts the distribution (probability) of context words from a center word.
2 training methods: negative sampling and hierarchical softmax.
Negative sampling defines an objective by sampling negative examples, while hierarchical softmax defines an objective using an efficient tree structure to compute probabilities for all the vocabulary.
为今后的研究奠定基础,我们和相对简单的模型设计了一组高度显著的特征。我们提出了两种模型,在噪声数据上训练,在人工标注数据集上评估。第一个是二分类模型,单独的对给定的代码块的每一个元素进行分类,判断它是否与相关注释中的指定名词短语相关联。第二个是序列标记模型,特别是一个条件随机场 CRF 模型,它共同为代码中的元素分配标签,其中标签表示一个元素是否与指定的名词短语相关联。我们设计了一套新颖的特征来捕获上下文表示、余弦相似度以及与编程语言相关的 API 和语法。
在噪声数据上训练,两种模型的表现大大优于基线,二值分类器获得 F1 score 0.677,CRF 获得 F1 score 0.618,分别比基线提高了39.6%和27.4%。我们通过随着噪声训练数据量的增加,模型的性能提升来证明噪声数据的价值性。此外,通过消融研究,我们强调了模型所用的特征的实用性。本文的主要贡献如下: